

Nowadays, everyone is talking about browser fingerprinting. The EU will adapt its current legislation so that device fingerprinting is treated analogous to the set of cookies (reference). This step is not only useful but essential to regulate the escalating tracking of users, but it only corresponds to the legislature. With the development of technology and the involvement of more and more new partners in the tracking industry, new ways and techniques are being tested to track an individual user even across multiple devices. How this can work exactly? We will explain it in the following article.
The general idea is to shift the tracking mechanisms into a lower technological layer. Currently, the tracking is mostly done on the client side through cookies or browser fingerprinting. Sometimes unlawfully IP is also utilized as a tracking ID. Now, if one tries to merge different device at this level it won’t sum up. Taking the tracking on a lower level like the network traffic, tracking may also work device-independently. The NSA has a similar approach to repeal the TOR anonymization. As a result, interference can be minimized and a slight cross-device detection is made possible. We all know that the matching on IP level is stochastically insecure almost comparable to the arbitrary guessing. While it is possible to match on households with a higher assuredness, the efficiency rate for the user-based matching is lower. It corresponds to another use case. Therefore, a possibility would be to analyze the browsing behavior of a user to be able to uniquely identify him or her. This process is as interesting as dangerous because a great abuse can be operated with it. We would like to explain the process in short.
How do you identify users due to their network traffic?
As we have shown in the article “browser fingerprinting”, almost every browser is unique. This can be analyzed through the appropriate choice of different device parameters. But it also applies to any individual. We know from the analysis of behavior that people always fall into similar behavioral patterns but the individual expression is always unique. This is partly due to the capacity limits in the progress of decision making (according to studies by Collins & Koechlin in neuropsychology) but especially with the fact that people always fall into a routine processes, as this allows behavior safety and the possibility to redirect partly focus elsewhere by the release of cognitive resources. This phenomenon is known in neuropsychology as System 1 [ref 1]. In our case this characteristic is now being used to precisely detect behavioral patterns by analyzing the network traffic in order to uniquely identify a user. This may sounds very abstract, therefor a short example:
Think about your daily first moves in the internet. In the first minutes many fetch their favorites news sites, check their emails or the local weather, read articles of a particular genre or chat with friends and colleagues via instant messenger.
This routine is mostly kept the same over a long period of time and changes happen more slowly than abrupt. Here, the exact article or message content is rather irrelevant, much more interesting are the technical communication partners, so the news page (e.g. CNN) or the media platform (e.g. Google Chat, Whatsapp). Through a profound analysis of network traffic, a pattern in the behavior can now be detected and these patterns can then be compared with each other and associated with a user. Without knowledge of the user, since the tracking does not act on the client side. As soon as a user changes the device, but the usage behavior remains the same, he or she can still be identified.
What is the difference between a browser fingerprint and a network fingerprint?
|
(Source: http://en.wikipedia.org/wiki/Internet_protocol_suite) | 
(Source: http://www.element14.com/community/static/knode/operating_systems/OS) |
|---|
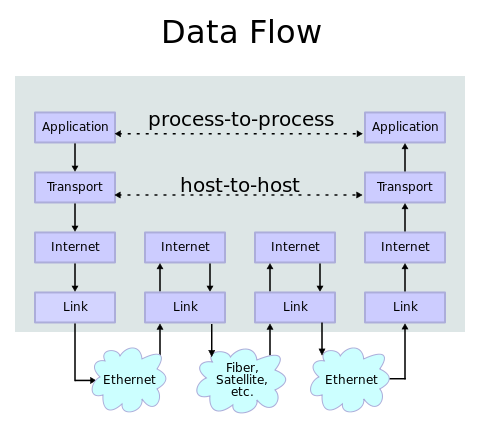
Normally, device or browser tracking is based on the Application layer within the TCP/IP Stack. If we now consider the equivalent view on OS level, the browser fingerprinting is done at the highest layer (Application). This is due to the fact that, in the process of generating the fingerprint, the code snippet has to access “publicly available information” from the user. This can be, for example, the screen resolution, color set or Internet speed. It usually requires active interaction with the user if one would rely on a deeper layer during the generation of the fingerprint. The latter applies to be avoided regarding scaling reasons. By using the network fingerprint we become independent from the mentioned OS stack, while reaching back to a lower layer within the TCP IP stack (Transport). This allows us a more flexible approach and brings us a device-independent identification of a user. Admittedly, the realization of the behavioral pattern recognition based on the network traffic is relative complex.
Future Work
In the following months, we will start a project to test the effectiveness of this approach. For this purpose we are going to provide a free gateway (squid proxy). If you would like to participate in this project feel free to get in touch with us directly. Once we have a presentable results we will share them with you. Be curious.
Dashboard: http://frauddb.framsteg.de/bpt-network-fingerprinting/statistics.php
[ref 1] If you want to know more about psychological human behavior patterns we recommend “Thinking, Fast and Slow” by Daniel Kahneman
