

The Problem
Recently I talked to a friend of mine who is about to initialize the kickoff of his new affiliate platform with the focus on the gaming industry. We talked about the potential of this market which we were able to notice during the releases of Battlefield 4, GTA 5 and Call of Duty Ghost. The sale of these games brought together more than one and a half billion Euro already on the first day. But we also talked about the risk of affiliate marketing or rather a well known problem in this context. No, I don't mean the step of recruiting publishers or winning advertiser, rather we discussed the matter of click fraud and potential lawsuit outcomes.
Did you ever imagine what could happen if an advertiser cancels a contract due to click fraud or "bad traffic"? They don't just get their investments back, no, they also get damage compensation for non-pecuniary damage and compensation for consequential loss (claims under §§ 249, § 253 BGB German Federal Law). Lets say, someone pays you $1000 for advertising purposes and this campaign ends in smoke, the affiliate platform could have to pay twice as much back if it doesn't take care of click fraud. Of course this does not mean in every case of click fraud the advertiser gets his money back but this implies that the third party in this triangular relationship - the affiliate platform - has to consider the topic of inhuman traffic in their product.

UML Use Case
So what could be a possible solution?
Because this is a major topic for some start ups, we would like to help. We thought about providing our knowledge on this topic to anyone who needs help, but - as far as we can overlook it - the requests which we received were far too many. Therefore we would like to develop a SaaS which is free and limited to all the startups out there. The setup is pretty simple. We are currently developing the API interface which receives JSON strings as request methods. In order for your algorithms to work correctly we need a couple of informations which can be found above. The general setup looks like that:
1) you may send us the necessary data automatically
2) we will parse them
3) let our algorithm calculate the probability that your user is a fraudster
4) or the probability if your commission is invalid or bad traffic
5) and return these values as percentage to you.

UML Sequence Diagram
Our goal is it to achieve this process in less than 250 ms. The related server has a response time of 16ms. So something like ~218 ms for algorithms to calculate the correct value.
During the alpha stage our average response time was something like 700 ms, because each algorithm took over 200 ms for its calculation. So it was necessary to slap the algorithm a bit. Further we resort to the topic of pthreads in php. pThreads is an object oriented API that allows user-land multi-threading.
“Wait, a threaded objects ? A Stackable, Thread or Worker can be thought of, and should be used as a Threaded stdClass: A Thread, Worker and Stackable all behave in the same way in any context with a reference. Any objects that are intended for use in the multi-threaded parts of your application should extend the Stackable, Thread or Worker declaration. Which means they must implement run but may not ever be executed; it will often be the case that Objects being used in a multi-threaded environment are intended for execution. Doing so means any context ( that's Thread/Worker/Stackable/Process ) with a reference can read, write and execute the members of the Threaded Object before, during, and after execution.“
(Source: php.net)
Due to this changes, we were able to decrease our average response time up to 245 ms which is enough for right now.
After returning the percentage as the result of our calculations you can specify the benchmarks until when you will accept the commission or marking it as invalid. So if you think that a invalid click with the percentage of 50% is still valid, that is up to your decision horizon.
How does the technical engine look behind this API?
In order to accomplish this response time goal, we will work with a SAP HANA similar in memory database which imitates a relational database management system. The basic concept envisages that the database will be stored in the RAM. For secondary data we are using SSDs . As for the fact, that our resources are limited to less than a cluster there is no possibility for non startups to use this SaaS without costs.
What technical infrastructure is used?
Every single cluster slave server supports quad socket. Therefore it is possible to use up to 4 processors like the Intel® Xeon® processors E7-4800 family (10-Core) or AMD equivalent on its motherboard. http://www.supermicro.com/xeon_mp/
The motherboard also supports up to 1TB DDR3 1066/800 MHz ECC registered DIMM. The server have gigabit uplink (500 Mbits peak guaranteed).
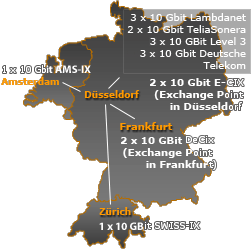
Backbone
But how do you determine whether a commission is invalid, fraud, or not?
That is a bit complicated. We are using multiple algorithms which work collaboratively on their task. Basically, there are 3 major layers:
1) Analyzing the origin of the traffic
2) Analyzing the circumstances and frame conditions of the commission
3) Analyzing the the behavior of the commission (including the behavior before and after the interaction)
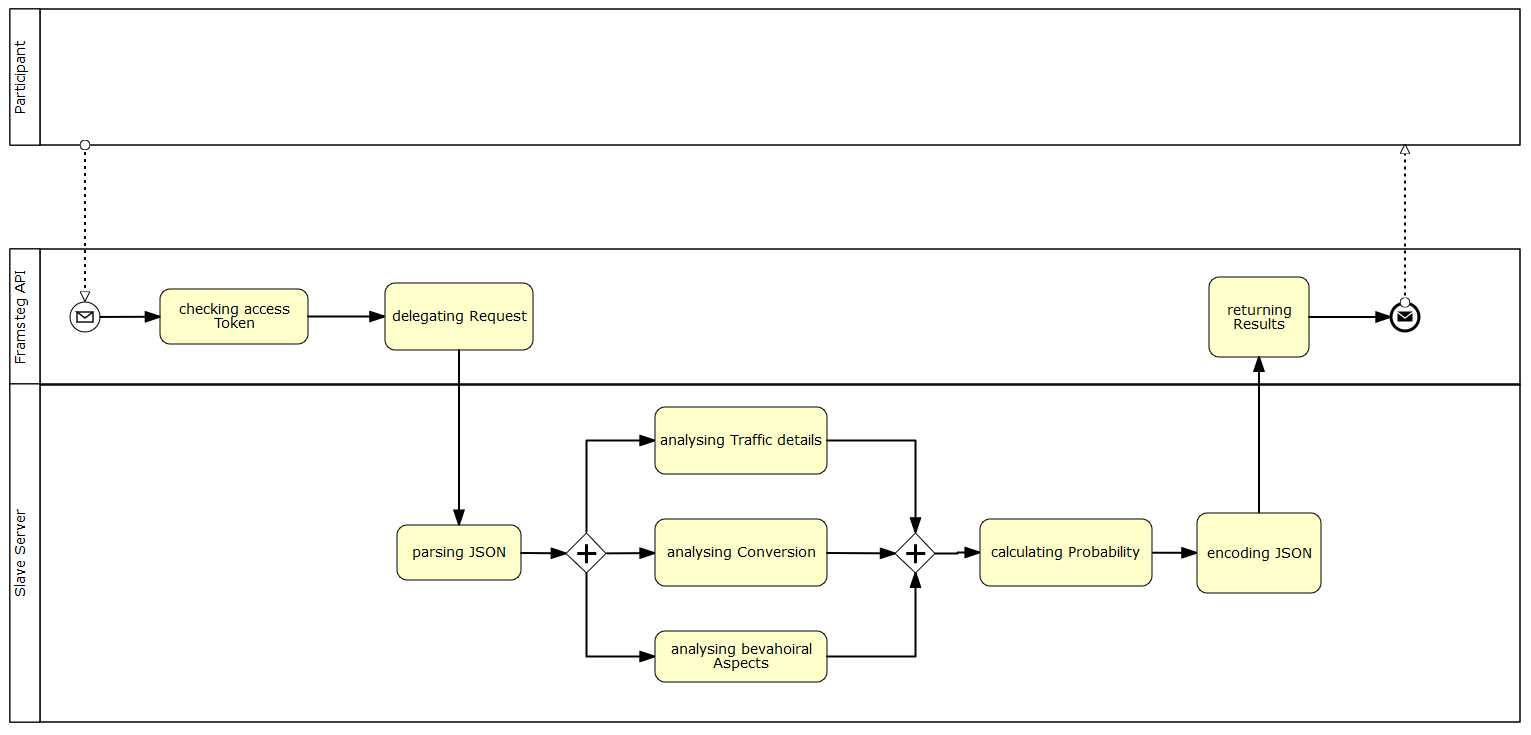
BPMN 2.0
Each of these 3 level targets a different step, which the potential fraudster has to manipulate in order to hide his commissions as good traffic. Additionally, we are also able to decide between bad or invalid traffic like a click on a dying advertising redirection link.
What makes our system unique and so promising?
Several factors. Firstly, we use various algorithms to detect the behavior of an impostor. Our system learns with the results. And we access both the publisher and the advertise parameter and user information to ensure the best possible result. But that is not far enough: One of our algorithms uses the Broken Windows Theory in combination with targeting method Predictable Behavioral Targeting. This algorithm operates on a matrix which gets automatically and continuously updated with social media data collected by a crawler. Through this fresh supply of comparative values we are able to increase the efficiency of our matching groups and take also into account the social and cultural changes in user behavior.
How does the JSON String look like?
The following table displays the parameter of the JSON String.
|
Value |
Description* |
|||||||||||||||||||||||||||||||||
|
1 |
$_SERVER as array with:
In addition, you can also send the entire $_SERVER array and we parse the requested informations from it. |
|||||||||||||||||||||||||||||||||
|
2 |
Target URL - of the advertising campaign |
|||||||||||||||||||||||||||||||||
|
3 |
Affiliate Redirection URL - if publisher & advertiser ID is included |
|||||||||||||||||||||||||||||||||
|
4 |
publisher ID - hashed is also fine |
|||||||||||||||||||||||||||||||||
|
5 |
advertiser ID - hashed is also fine |
|||||||||||||||||||||||||||||||||
|
6 |
Cookie ID - hashed is also fine |
|||||||||||||||||||||||||||||||||
|
7 |
User ID - if available / hashed is also fine |
* Description taken from php.net
Sample JSON String:

The data structure:

You can check your JSON String here
How does the response look like?

The data structure:

|
Value |
Description* |
||||||
|
1 |
Result of the request isFraud
|
||||||
|
2 |
is the percentage of the result. e.g. 90 means with 90% the request is the value (for “0” no fraud) |
What about privacy?
We are following one of the best information privacy systems in the world according to the German case law. No personal information will be stored. None. At all. However, these provided information will be cached for the calculation time of about 500 ms.
Where is the API?
API Interface: http://api.framsteg.de/interface.php?atoken=yourToken
Current evaluation of the project
Here, you can find the current statistics for this project. The analysis contains the amount of detected fraud clicks, the amount of invalid or non intended clicks, accuracy and so on.. just have a look:
http://frauddb.framsteg.de/prevention-api/statistics.php
Do you like our project? Or want to participate in our anti fraud pattern? Just send us a quick note and we will setup an access token for you! :)
